조금 더 빠른 시계열 예측
시계열 예측 관련 공부를 하며 walking forward validation을 사용하는 경우가 발생하게 되었는데, 기존 데이터가 너무 커서 시간이 너무 오래걸리는 문제를 느꼈다.
그래서 과연 어떻게 하면 빨리 모델링을 할 수있을까? 확인해보고자 했다.
forecast 패키지를 활용하여 성능 비교를 해보자.
먼저 사용된 패키지는 data.table, zoo, forecast를 활용하였다.
time3=system.time({
ls=list()
for(i in 1:25){
message(i)
ls[[i]]=data.frame(forecast(auto.arima(AirPassengers[1:(120+i-1)],ic='aicc',stepwise=F),12))[,1]
temp3=t(bind_cols(ls))
}
})

먼저 for문을 통해 시간을 계산 한 결과 11초 정도가 나타났다.
다음은 lapply문을 활용한 결과 큰 차이는 나지 않으나 조금 빨라진 모습을 볼 수 있다.
time4=system.time({
ls2=list()
for(i in 1:25){
ls2[[i]]=AirPassengers[1:(120+i-1)]
}
temp4=lapply(ls2,function(x){data.frame(forecast(auto.arima(x,ic='aicc',stepwise=F),12))[,1]})
})
다음은 zoo 패키지의 rollapply를 사용한 결과이다. 조금 더 빨라진 모습을 볼 수 있다.
library(forecast)
time1=system.time({
dt=data.frame(temp=AirPassengers)
setDT(dt)
temp1=dt[,rollapply(temp,120,function(x){data.frame(forecast(auto.arima(x,ic='aicc',stepwise=F),12))[,1]})]
})
다음은 data.table 패키지를 활용한 결과이다.
time1=system.time({
dt=data.frame(temp=AirPassengers)
setDT(dt)
temp1=dt[,rollapply(temp,120,function(x){data.frame(forecast(auto.arima(x,ic='aicc',stepwise=F),12))[,1]})]
})
끝으로 아래 포스팅에서 본 여러개의 시계열 모델을 빠르게 예측하는 방법을 올리고 포스팅을 마치겠다.
https://statkclee.github.io/statistics/stat-time-series-forecast.html
Software Carpentry: 데이터 과학 – 기초 통계
데이터 과학 – 기초 통계 시계열 데이터 예측(forecast) 학습 목표 시계열 데이터의 백미 예측을 살펴본다. 다양한 시계열 데이터 모형의 장단점을 비교한다. 자동 시계열 예측의 필요성을 이해한
statkclee.github.io
'통계 > time series' 카테고리의 다른 글
| 시계열 용어 정리 (0) | 2020.07.15 |
|---|
anaconda 활용법
아나콘다에서 할 수 있는 것을 먼저 확인해보자.
conda -h
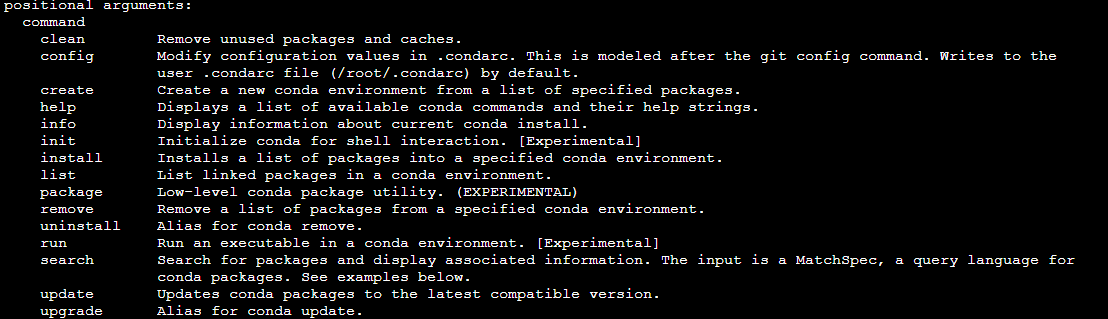
conda --version : 아나콘다 버전확인

위와 같이 다양한 것을 할 수 있다.
자 이제 실제로 유용하게 쓸 수 잇는 목록을 크게 생성, 제거, 복구로 나누어 생각해보자.
생성 하기 전에 목록을 확인하는 방법은 다음과 같다.
conda env list : 가상환경 목록 확인

생성
conda create -n [가상환경이름] python=[버전 ex) 3.6]
-> conda create -n test python=3.6

-y를 붙여 주면 질문을 무시하고 생성할 수 있다.

가상환경을 쓸지 말지 위와같이 설정할 수 있다.
파이썬의 경우 패키지에 따라 함수가 없는 경우가 존재하므로 깔려 있는 패키지 목록과 버전을 확인해보자.

환경을 공유하기 위해서 가상환경에 설치된 환경을 추출해보자.


추출한 환경 목록으로 설치해보자.

삭제
백업
conda list --revisions
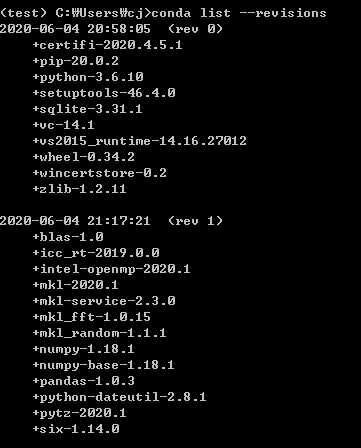
conda install --revision [revision num]

conda는 SQL의 savepoint와 다르게 새로 백업을 해도 savepoint보다 미래인 환경으로 돌아 갈 수 있다.

conda remove -n [가상환경] --all

주피터 노트북 커널 추가
conda create -y -n [가상환경명] ipykernel

python -m ipykernel install --user --name [가상환경] --display-name "등록될 이름"

jupyter kernelspec list
jupyter kernelspec remove [커널이름]
python -m ipykernel install --user --name pytorch --display-name "표출되고 싶은 커널 이름"
'python' 카테고리의 다른 글
| 명령프롬프트로 anaconda 열기 (0) | 2020.07.01 |
|---|---|
| pandas-profiling (0) | 2020.06.11 |
| [postgreSQL] python에서 postgreSQL과 shape file 사용하기 (0) | 2020.03.15 |
| python 메일 보내기 (0) | 2020.02.24 |
| jupyter notebook 가상환경에 basemap 설치하기 (0) | 2020.02.23 |




'머신러닝' 카테고리의 다른 글
| 보루타(boruta algorithm) (0) | 2020.08.09 |
|---|---|
| Dynamic Time Warping(동적 시간 접합) (0) | 2020.07.09 |
| 과적합이 좋지 못한 이유? (0) | 2020.01.20 |
| 정형데이터마이닝 - 비지도학습 (0) | 2019.07.04 |
| 데이터마이닝 개요와 R 기초 사용법 (0) | 2019.07.04 |
ubuntu LightGBM install
https://github.com/microsoft/LightGBM/tree/master/R-package
microsoft/LightGBM
A fast, distributed, high performance gradient boosting (GBT, GBDT, GBRT, GBM or MART) framework based on decision tree algorithms, used for ranking, classification and many other machine learning ...
github.com
sudo apt install cmake
devtools::install_github("Laurae2/lgbdl")
아래 코드로 설치관련 패키지를 설치한다.
위는 gpu 버전을 필요로할 때
lgb.dl(commit = "master", compiler = "vs", # Remove this for MinGW + GPU installation repo = "https://github.com/microsoft/LightGBM", use_gpu = TRUE)
아래는 cpu버전을 활용할 때 사용하면 된다.
lgb.dl(commit = "master", compiler = "vs", repo = "https://github.com/microsoft/LightGBM")
'ubuntu' 카테고리의 다른 글
| ssh 등록하기 (0) | 2020.11.12 |
|---|---|
| ubuntu 20.04 세팅하기[gpu 분석 세팅, jupyter notebook] (0) | 2020.11.12 |
| 라즈베리파이 selenium 사용법 (0) | 2020.03.23 |
| nas 마운트하기 (0) | 2020.03.23 |
| 라즈베리파이 openCV 설치 및 관절 인식 (2) | 2020.02.13 |
[파이썬 ] 한글 자동화 보안모듈 등록
https://www.hancom.com/board/devdataView.do?board_seq=47&artcl_seq=4085&pageInfo.page=&search_text=
글로벌 소프트웨어의 리더, 한글과컴퓨터
◎ 첨부파일(보안모듈(Automation).zip)을 다운받으시고 압축을 해제 하시기 바랍니다. 구성물은 다음과 같습니다. 1. 보안모듈 소스 2. 보안모듈(FilePathCeckerModuleExample.dll) 3. 보안모듈 등록위치(레지스트리.JPG) 보안모듈을 특정위치에 설치하신 후, 레지스트리.JPG의 내용처럼, 보안모듈의 이름과 풀패스를 레지스트리 등록하신 뒤 사용하시기 바랍니다. 추가로 프로그램 소스에
www.hancom.com
C:\Program Files (x86)\Hnc//program files/Automation_Module 폴더 생성(폴더 명 무관)
압축 푼 파일 다운로드
경로 복사
(shift + F10 )>a
레지스트리 편집기 실행( regdit 입력)
HKEY_CURRENT_USER>Software>HNC>HwpAutomation>Modules
혹시 없는 경로가 있다면 키를 생성하여 정확한 이름 입력
Modules에 새로 만들기> 문자열값
이름은 기억하기 쉬운것으로(SecurityModule)로 저장
수정>값 데이터에 아까 복사한 경로를 붙여넣고 "을 제거하여 저장
https://www.youtube.com/watch?v=2Cv16_ZO5rk&list=PLalzN02jITUtke62DP2PHZ6mkDid72IC_&index=5
#shift alt h
#shift alt x
#shift alt l
#alt c
'python > hwp' 카테고리의 다른 글
| win32com.client CLSIDToPackageMap 에러 해결 (0) | 2020.06.09 |
|---|
