전이학습(Transfer Learning)
전이학습이란?
전이 학습의 아이디어는 이미 구축된 잘 만들어진 모형을 활용하자는 아이디어에서 비롯됬다.
즉, 이미 훈련된 모델(Pre trained Model)의 가중치를 가져와 해결하고자 하는 과제에 맞게
재보정해서 사용하는 것을 의미하며, 일부 레이어를 고정하고 나머지 레이어에 대해 추가 교육을
수행하여 목적에 맞게 조정하는 방법이다.
전이학습의 장점은 완성된 모델을 사용하므로 하드웨어가 부족하더라도 사용이 가능하다는 장점이 있다.
Learning from scratch
일반적으로 모델을 학습하는 방식으로 처음부터 모델의 가중치를 학습하는 방식을 의미한다.
Pre trained model
내가 풀고자하는 문제와 비슷하며 사이즈가 큰 데이터로 이미 학습되어 있는 모델을 의미한다.
보틀넥 피쳐(Bottleneck feature)
가장 마지막 CNN 블록을 의미하며, Fully connected layer 직전의 CNN블록의 결과를 의미한다.
Fine Tuning
전이학습을 Fine Tuning용어와 같이 혼용되곤 한데 Fine Tuning은 일부 레이어의 가중치 고정을 해제하고
학습율을 줄여 파라미터를 미세 조정하는 방법을 의미한다.
피처를 추출해내는 레이어의 파라미터를 업데이트하지 않는 경우 파인튜닝이라 하지 않는다.
'딥러닝' 카테고리의 다른 글
| 기울기 소실 문제와 ResNet (0) | 2021.05.25 |
|---|---|
| 순환신경망(1/3) (0) | 2021.04.11 |
| tensorboard 외부접속 (0) | 2020.11.27 |
| GPU 메모리 조절 방법 (0) | 2019.11.19 |
| CNN channel 1개와 3개의 성능비교(cats and dogs) (0) | 2019.06.18 |
기울기 소실 문제와 ResNet
기울기 소실 문제(Gradient Vanishing Problem)
학습과정에서 출력값과 멀어질수록 학습이 잘 안되는 현상
레이어가 깊어질수록 미분 많아지므로 오차역전파(Backpropagation)를 진행해도
앞의 레이어일수록 미분값이 작아져 그만큼 출력값(Output)에 영향을 미치는 가중치가 작아지는 현상
기울기 소실문제의 해결 방안으로 그라디언트 클래핑, 다양한 활성화함수(swish, mish) 등이 제시
ResNet
기존 딥러닝 알고리즘은 y=H(x)를 찾는 과정이였다면,
ResNet은 H(x)-y를 최소화 하는 방향으로 진행하며,
기울기 소실 문제를 해결하기 위해서 F(x)+x=H(x)로 하고, F(x)=0이 되게 학습을 진행
F(x)+x의 미분값은 F'(x)+1이므로 모든 층에서 적어도 1이상의 gradient를 가지게 됨

'딥러닝' 카테고리의 다른 글
| 전이학습(Transfer Learning) (0) | 2021.05.25 |
|---|---|
| 순환신경망(1/3) (0) | 2021.04.11 |
| tensorboard 외부접속 (0) | 2020.11.27 |
| GPU 메모리 조절 방법 (0) | 2019.11.19 |
| CNN channel 1개와 3개의 성능비교(cats and dogs) (0) | 2019.06.18 |
순환신경망(1/3)
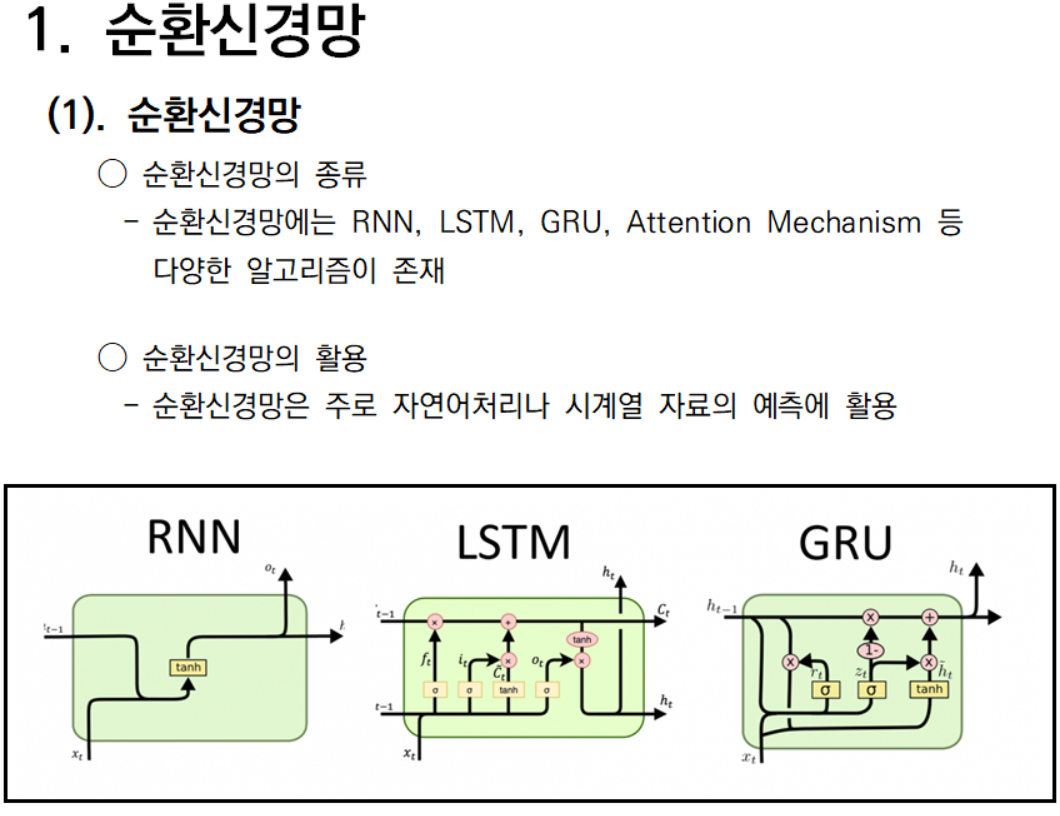





'딥러닝' 카테고리의 다른 글
| 전이학습(Transfer Learning) (0) | 2021.05.25 |
|---|---|
| 기울기 소실 문제와 ResNet (0) | 2021.05.25 |
| tensorboard 외부접속 (0) | 2020.11.27 |
| GPU 메모리 조절 방법 (0) | 2019.11.19 |
| CNN channel 1개와 3개의 성능비교(cats and dogs) (0) | 2019.06.18 |
[Selenium] 기상자료 크롤링
크롤링의 종류와 개요는 아래에 포스팅 해두었으니, 궁금하신 분은 먼저 읽고 오기를 바란다.
크롤링과 python
크롤링, 스크래핑 데이터 분석의 자료수급을 위해 요즘 같이 활용되는 기술로 크롤링이라 부르는 기술이 있다. 크롤링은 크롤러가 웹을 돌아다니는 작업을 말하고, 스크래핑은 크롤러를 통해
pycj92.tistory.com
사용될 패키지
크롤링에 사용될 패키지는 다음과 같으며, 간단한 용도는 다음과 같다.
자료 저장 경로나 디렉토리조회 관련 용도의 os 패키지
자료 추출을 위한 re 패키지
크롤러에 지연을 주기위한 time 패키지
원하는 곳으로 파일 이동을 위한 shutil 패키지
사용하지는 않았지만, 향후 자동로그인을 위한 threading 패키지
마지막으로 크롤링에 사용되는 selenium 패키지
import os
import re
import warnings
from time import sleep
import pandas as pd
import shutil
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import Select
import threading 사용 환경 설정
본격적인 크롤링에 앞서, 환경을 세팅해보자.
환경을 세팅하기 위해서는 크롬드라이버를 별도로 다운로드 받아야하는데 사용하고 있는
크롬의 버전과 동일해야 한다.
아래는 크롬드라이버의 버전을 확인하는 과정이다.
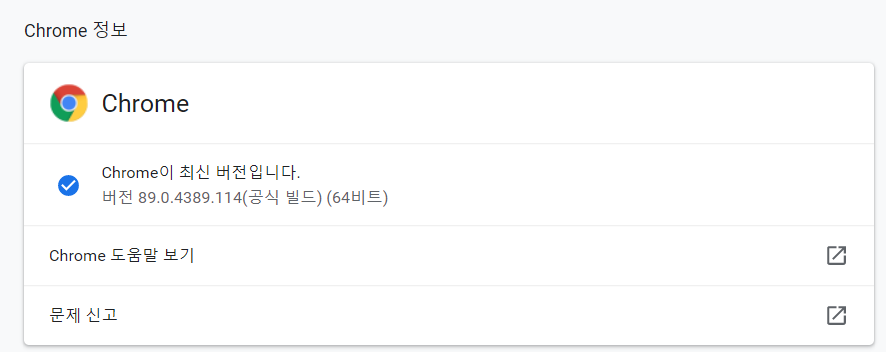
현재 내 컴퓨터는 89.0 버전이라는 것을 확인할 수 있다.
아래 링크는 크롬드라이버를 설치할 수 있는 사이트이다. 해당 사이트에서 내 버전인 89.0 windows 버전으로 다운받자.
chromedriver.chromium.org/downloads
Downloads - ChromeDriver - WebDriver for Chrome
WebDriver for Chrome
chromedriver.chromium.org
다운 받았다면, 다운받은 chromedriver.exe파일을 자주사용하는 경로로 이동시키도록 하자
(나는 c:/selenium으로 설정함, c:/selenium/chromedriver.exe)
본격적인 크롤링
간략히 설명하자면, driver_path는 chrome driver의 경로를 의미하며, download_path는
인터넷의 자동 다운로드 경로를 의미한다.
setting함수를 사용하게 되면, 기상자료개방포털 홈페이지로 이동하게 된다.
login 함수를 사용하게 되면, login을 수행하며, 성공하면 True를 반환한다.
logout 함수를 사용하게 되면, logout을 수행하며, 성공하면 True를 반환한다.
close와 quit함수는 인터넷창을 닫는다.
class KMA:
def __init__(self,driver_path=r'c:\selenium\chromedriver.exe',
download_path=r'D:\downloads',options = Options(),time=5):
self.down_dir=download_path
self.driv_path=driver_path
self.options=options
options.add_experimental_option("prefs", {
"download.default_directory": self.down_dir})
self.time=time
self.thread=threading.Timer(time,self.auto_login)
def setting(self):
try:
self.driver.quit()
except:
1
self.driver= webdriver.Chrome(self.driv_path, options=self.options)
self.driver.get('https://data.kma.go.kr/cmmn/main.do')
def login(self,kma_id,kma_pass):
try:
self.driver.maximize_window()
self.driver.find_element_by_css_selector('a#loginBtn').click()
self.driver.find_element_by_css_selector('input#loginId.inp').send_keys(kma_id)
self.driver.find_element_by_css_selector('input#passwordNo.inp').send_keys(kma_pass)
self.driver.find_element_by_css_selector('button#loginbtn.btn_login').click()
return True
except:
print('이미 로그인 중입니다.')
return False
def logout(self):
try:
self.driver.maximize_window()
self.driver.find_element_by_css_selector('a#logoutBtn').click()
return True
except:
print('이미 로그아웃 되어있습니다.')
return False
def close(self):
self.driver.close()
def quit(self):
self.driver.quit()
login, logout 을 매번 수행하기 귀찮으므로 login_loof함수를 사용하게 되면 다시 로그인을 수행한다.
auto_login, start, cancel함수는 현재 수정중이다.
download는 자료를 다운로드 받는 함수이다.
data_type은 지상기상관측자료와 해양자료 즉, Aws, Asos, Agr, FargoBuoy, Buoy, Rh가 될수 있으며,
new_path는 최종적으로 저장될 경로를 의미하고, time_type은 시간자료, 분자료, 일자료 등이 될 수 있다.
def login_loof(self,kma_id,kma_pass):
self.logout()
self.login(kma_id,kma_pass)
def auto_login(self,kma_id,kma_pass):
self.login_loof(kma_id,kma_pass)
self.thread=threading.Timer(self.time,self.auto_login)
self.thread.start()
def start(self):
self.thread.start()
def cancel(self):
self.thread.cancel()
def download(self,data_type,download_day,new_path,query,time_type='시간 자료'):
""" 사이트 이동 """
try:
if data_type in ['Aws','Asos','Agr']:#Asos,Aws,Agr
self.driver.get(f'https://data.kma.go.kr/data/grnd/select{data_type}RltmList.do?pgmNo=')
elif data_type in ['FargoBuoy','Buoy','Rh']:#data_type='FargoBuoy'#Buoy,lb(Rh),FargoBuoy
self.driver.get(f'https://data.kma.go.kr/data/sea/select{data_type}RltmList.do?pgmNo=')
else:
raise
except:
print('Asos, Aws, Agr, FargoBuoy, Buoy, Rh')
""" 시간 타입 """
Select(self.driver.find_element_by_id('dataFormCd')).select_by_visible_text(time_type)
""" 변수 선택 """
self.driver.find_element_by_id('ztree1_1_check').click()
""" 전체 지점 선택 """
if self.driver.find_element_by_css_selector('a#ztree_1_check').get_attribute('title')=='전체선택 안됨':
self.driver.find_element_by_css_selector('a#ztree_1_check').click()
""" 시작 기간 설정 """
self.driver.execute_script('document.querySelector("input[id=startDt_d]").removeAttribute("readonly")')
self.driver.execute_script(f'document.querySelector("input[id=startDt_d]").value = "{query}"')
""" 끝 기간 설정 """
self.driver.execute_script('document.querySelector("input[id=endDt_d]").removeAttribute("readonly")')
self.driver.execute_script(f'document.querySelector("input[id=endDt_d]").value = "{query}"')
if time_type=='시간 자료':
self.driver.find_element_by_xpath(f'//select[@name="startHh"]/option[@value="{st_time}"]').click()
self.driver.find_element_by_xpath(f'//select[@name="endHh"]/option[@value="{ed_time}"]').click()
""" 조회 """
self.driver.execute_script('goSearch();')
sleep(1)
if data_type=='FargoBuoy':
pd.read_html(self.driver.find_elements_by_css_selector('table.tbl')[0].get_attribute('outerHTML'))
else:
pd.read_html(self.driver.find_elements_by_css_selector('table.tbl')[1].get_attribute('outerHTML'))
""" 다운로드 """
self.driver.execute_script('downloadRltmCSVData();')
sleep(1)
try:
self.driver.find_element_by_css_selector('div#divPopupTemp.back_layer').get_attribute('id')
self.driver.find_element_by_id("reqstPurposeCd7").click()
except:
1
self.driver.execute_script('fnRltmRequest();')
#A.quit()
before_files=[i for i in os.listdir(self.down_dir) if re.compile('.csv').findall(i)]
before=(len(before_files))
sleep(5)
after_files=[i for i in os.listdir(self.down_dir) if re.compile('.csv').findall(i)]
after=(len(after_files))
if before!=after:
down_file=list(set(after_files)-set(before_files))[0]
shutil.move(f'{self.down_dir}/{down_file}',new_path)
자료를 하루만 받을게 아니라서, download_range함수를 만들었다.
n_download_login_loof는 '자료를 몇개 받았을 때 재로그인할지'에서 몇개를 의미한다(default : 20)
over_write는 기존에 같은 자료가 있으면, 넘어갈지 덮어쓸지를 의미한다.
def download_range(self,date_list,data_type,kma_id,kma_pass,\
n_download_login_loof=20,st_time='00',ed_time='23',time_type='시간 자료',\
down_dir='d:/downloads/aws',over_write=False):
_n_download_login_loof=0
down_error=list()
old_down_dir=os.listdir(down_dir)
for download_day in date_list:
_n_download_login_loof=_n_download_login_loof+1
if _n_download_login_loof%n_download_login_loof==1:
self.login_loof(kma_id,kma_pass)
sleep(3)
query=download_day.strftime('%Y%m%d')
move_file_name=f'{data_type}_{query}_{time_type}.csv'
new_path = f'{down_dir}/{move_file_name}'
n_download_login_loof=n_download_login_loof+1
if over_write==False:
if not move_file_name in old_down_dir:
try:
print(download_day)
self.download(data_type,download_day,new_path,query,time_type)
except:
down_error.append(download_day)
else:
try:
print(download_day)
self.download(data_type,download_day,new_path,query,time_type)
except:
down_error.append(download_day)
return down_error
def date_to_filename(self,date_list,down_dir, data_type, time_type):
return [f'{data_type}_{i.strftime("%Y%m%d")}_{time_type}.csv' for i in date_list]
대충 사용방법은 아래를 따라하면 된다.
A=KMA(time=60*3,download_path=r'D:\downloads\temp')
#A=KMA(time=60*3)
A.setting()
A.login_loof(kma_id=아이디,kma_pass=비밀번호)
start_day = '2010-01-01';end_day = '2020-12-31';data_type='Asos'#Asos,Aws
st_time='00';ed_time='23';time_type='시간 자료';down_dir='d:/downloads/asos';over_write=False
start_day = pd.Timestamp(start_day)
end_day = pd.Timestamp(end_day)
date_list=pd.date_range(start_day,end_day,freq='d')
#start_day = pd.Timestamp(start_day)
#download_day=start_day
#query=download_day.strftime('%Y%m%d')
#move_file_name=f'{data_type}_{query}_{time_type}.csv'
#new_path = f'{down_dir}/{move_file_name}'
#A.download(data_type,download_day,new_path)
down_error_list=A.download_range(date_list,data_type,n_download_login_loof=20,\
kma_id=아이디,kma_pass=비밀번호,down_dir='d:/downloads/asos')
#query=download_day.strftime('%Y%m%d')
set(A.date_to_filename(date_list, down_dir, data_type, time_type))-set(os.listdir(down_dir))
A.quit()
'python > crawling' 카테고리의 다른 글
| 크롤링과 python (0) | 2021.04.03 |
|---|---|
| python selenium 자주쓴거 정리 (0) | 2020.03.23 |
| 나라장터 open api crawling (0) | 2020.03.01 |
| [나라장터] 크롤링 (2) | 2019.11.14 |
| selenium 사용해서 위경도 가져오기 (0) | 2019.03.20 |
크롤링과 python
크롤링, 스크래핑
데이터 분석의 자료수급을 위해 요즘 같이 활용되는 기술로 크롤링이라 부르는 기술이 있다.
크롤링은 크롤러가 웹을 돌아다니는 작업을 말하고, 스크래핑은 크롤러를 통해 자료를 수집하는 것을 의미한다.
물론 이게 완벽한 정의라고는 할 수 없을지도 모른다.
본론으로 들어가서 크롤링에는 동기식, 비동기식이 있다.
Python에서는 requests, urllib, BeautifulSoup, Selenium, Scrapy 등 이 대표적이다.
크게 웹을 이용하는 selenium을 활용하는 크롤링을 동적크롤링,
requests, urllib, BeautifulSoup을 활용한 크롤링을 정적 크롤링이라고 표현한다.
BeautifulSoup, requests, urllib 패키지
해당 패키지는 HTML, XML파일의 정보를 추출해주는 파이썬 패키지이다.
다소 안정적이고 빠르나, javascript가 필요한 크롤링이 제한된다.
Selenium 패키지
해당 패키지는 인터넷 브라우저를 통해 정보를 추출해주는 패키지이다.
실제 인터넷을 사용하므로, 다소 불안정하나, Javascript가 필요한 크롤링이 수월하다.
'python > crawling' 카테고리의 다른 글
| [Selenium] 기상자료 크롤링 (1) | 2021.04.03 |
|---|---|
| python selenium 자주쓴거 정리 (0) | 2020.03.23 |
| 나라장터 open api crawling (0) | 2020.03.01 |
| [나라장터] 크롤링 (2) | 2019.11.14 |
| selenium 사용해서 위경도 가져오기 (0) | 2019.03.20 |
코딩 스타일과 관리
코딩 스타일은 협업을 잘 하지 않는 내 입장으로써는 다소 생소하지만 중요한 내용이라 할 수 있다.
얼마 전 협업을 할 일이 있었는데, 그 때 몇 가지 중요시 해야할 것들을 느끼게 됬다.
첫 째, 변수명 및 조건문 표기법 설정둘 째, 중요 서비스 셋 째, 코드 난이도 설정 이 3가지의 중요성을 느꼈다.
변수명의 표기법 설정
우리가 코딩 할 때에는 여러 변수들을 설정하게 된다.
이러한 변수는 그 의미를 파악하기 쉬운 범위 내에서, 짧게 작성하는 것이 좋다.
변수 설정 규칙에는 크게 카멜 케이스, 파스칼 케이스, 스네이크 케이스로 나눌 수 있는데, 예를 들어 설명하면,
수온이라는 변수가 있다고한다면, Water Temperature라는 단어를
카멜 케이스는 waterTemp 혹은 wTemp로 표기,
파스칼 케이스는 WaterTemp 혹은, WTemp,
스네이크 케이스는 water_temp 혹은 w_temp로 표기한다.
카멜 케이스와 파스칼 케이스의 차이는 일반적으로 Class를 표기하는 경우 파스칼 케이스를 사용하며,
그렇지 않은 경우 카멜케이스를 사용하도록 한다.
조건문의 표기법 설정
조건문의 표기법은 크게 2가지로 나누어 진다. BSD 방법, K&R 방법, GNU 방법으로 나뉘는데, 표기는 아래와 같다.

중요 서비스 설정
얼마전 협업으로 진행하는 서비스는 AI를 현업화 단계까지 적용하는 서비스에 해당하였다.
따라서 서비스의 중요도는 규칙적으로 하루에 한 번 애러없이 실행되는 지속성과
운영될 컴퓨터에서 문제 없이 동일한 결과가 실행 가능한 재현가능성과
AI 예측모형의 높은 정밀도를 의미하는 정확도 측면이 중요하게 작용하였다.
코드 난이도 설정
해당 서비스에서는 높은 정밀도를 위해 여러가지 테스트를 해보고 결과를 도출하여야 하였다.
따라서 빠른 결과 도출이 중요하였다. 이에 따라 gpu와 병렬처리 코드들이 많이 활용되었는데,
그 때 당시 내 역량이 부족하여, 협업 코드를 같이 수정할 수 없었다.
그리고 결과적으로, 운영될 컴퓨터에서 재현가능하게 하기 위해서 새로 코드를 짜는 과정이 필요했다.
본론으로(코딩 스타일과 자동검사)
급할수록 돌아가라는 말이 있다.
이처럼 협업을 위해서는 여러가지 약속들을 정의하고 진행하는 것은 최종적으로 시간을 줄이는 결과를 가져옵니다.
협업을 통해 프로젝트를 잘 수행하기 위해서는 따라서 프로젝트의 설계가 몹시 중요하다.
프로젝트의 설계와 관리는 잘 알지 못하는 분야라 향후 포스팅을 하는 것으로 하고,
지금부터 다루게 될 내용은 python의 코딩 스타일과 코딩 오류의 자동 검사이다.
파이썬의 스타일
파이썬 개발자는 PEP 8이라는 스타일 가이드를 만들었다.

위와 같은 가이드가 있다. python에는 이미 이러한 가이드를 자동 검사하는 도구들이 있습니다.
anaconda.org/conda-forge/pycodestyle
Pycodestyle :: Anaconda.org
anaconda.org
pycodestyle
Python style guide checker
pypi.org
나는 anaconda를 활용하므로 이를 기반으로 스타일 오류 검사를 진행해 보겠다.
conda install -c conda-forge pycodestyle 로 pycodestyle을 설치했다.
나는 최근에 짠 코드를 확인하기 위해 D:/stock/2021/stock에 있는 main_1file_gen.py를 확인하여 보았다.
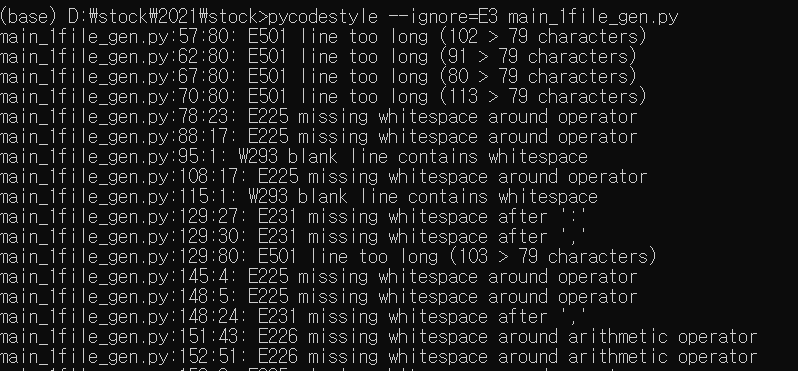
몇번 째 줄이 너무 길다. 등의 여러가지 문구들을 반환해 준다.
코딩 오류의 자동검사
코딩 오류를 확인해주는 툴은 Pyflakes, Pylint와 Pyflakes와 pycodestyle을 합친 flake8 등이 있다.
Pyflakes의 결과이다. 불필요한 패키지나 문법을 수정해준다.

pylint는 PEP8 적합성 또한 확인해 준다. 대신 Pyflake보다 느리다는 단점이 있다.
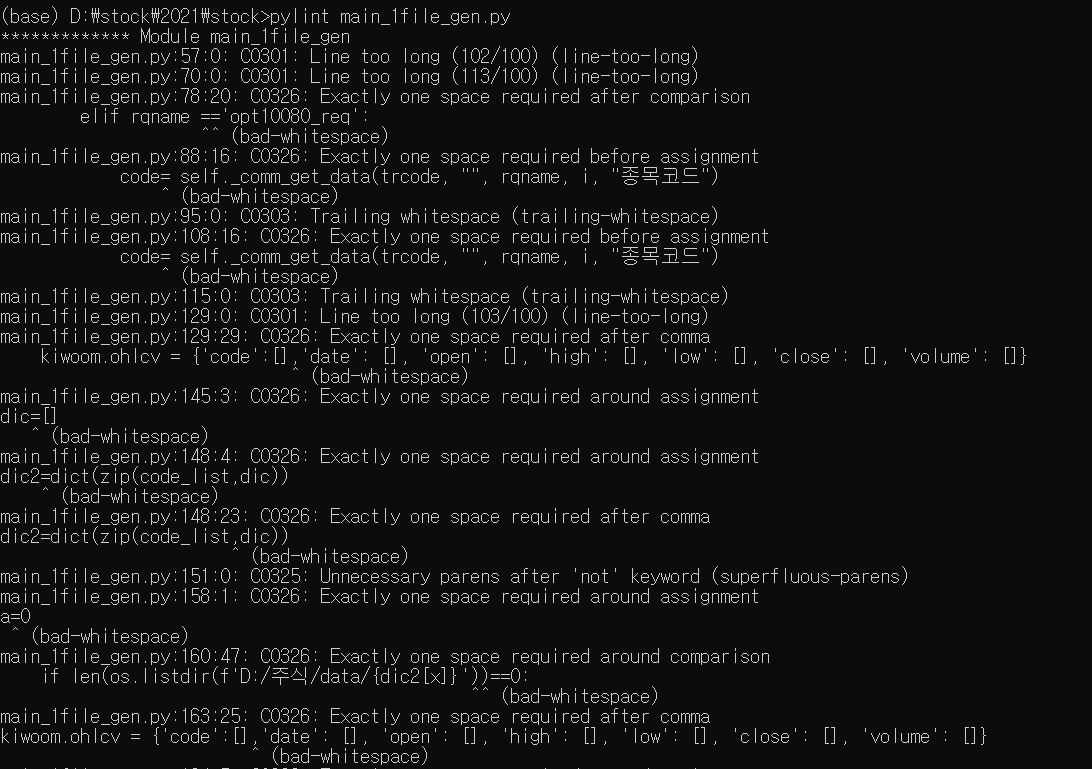
따라서 flake8을 사용하며 flake8은 다양한 플러그인이 존재한다고 한다.

누군가에게는 이러한 과정이 다소 불필요하고 의미 없어 보일수도 있다.
나도 그랬던 적이 있다. 제한된 시간 내에 어떠한 업무를 하기에 혼자서는 불가능한 경우가 분명히 존재한다.
그것이 공모전나 프로젝트든..
적어도 지금 나는 이러한 프로젝트의 관리가 잘되어 있으면, 향후 관리를 편하게 해 줄 수 있다고 생각한다.
해당 내용은 한빛 미디어 진지한파이썬 책을 참고하였습니다.
'python' 카테고리의 다른 글
| python을 시작하기 전에 (0) | 2021.02.27 |
|---|---|
| jupyter kernel 제대로 추가 안될 때 (2) | 2021.01.24 |
| python oracle DB 연동 (0) | 2020.12.03 |
| offline conda pack spyder설치 에러 (0) | 2020.12.01 |
| conda python 경로 인식못할 때 (0) | 2020.11.28 |
