[numpy install]
pypy3 -m pip install --extra-index-url https://antocuni.github.io/pypy-wheels/manylinux2010 numpy
'python' 카테고리의 다른 글
| pyinstaller (0) | 2020.11.20 |
|---|---|
| matplotlib 시각화 정리 [여러 그림 그리기, quiver plot] (0) | 2020.11.05 |
| python package 생성 (0) | 2020.08.17 |
| python gridSearch, RandomSearch (0) | 2020.07.30 |
| 명령프롬프트로 anaconda 열기 (0) | 2020.07.01 |
python package 생성
pip는 Python Package Index(PyPI)를 일컷는 약자로 파이썬 패키지를 관리하는 패키지 저장소이다.
우선 단계를 구분하자면
0. pypi 계정 생성, git 계정 생성
1. github repository 생성
2. 사용할 함수 및 폴더 구성
3. setup.py, __init__.py, README.md, setup.cfg, .gitignore, git init 생성
4. 등록
5. 사용
1. github repository
github 들어가서 아래처럼 Repository를 생성한다. 가급적 이름은 패키지랑 동일한게 좋으나 달라도 무방하다.

pca_cj 가 생성할 package name이며, 사용할 함수 및 폴더 구성은 다음과 같다.
<package name>
ㄴ<package name>
ㄴfunction1.py
ㄴfunction2.py


setup.py
from setuptools import setup, find_packages
setup(
# 배포할 패키지의 이름을 적어줍니다. setup.py파일을 가지는 폴더 이름과 동일하게 합니다.
name = 'pca_cj',
# 배포할 패키지의 버전을 적어줍니다. 첫 등록이므로 0.1 또는 0.0.1을 사용합니다.
version = '0.2',
# 배포할 패키지에 대한 설명을 작성합니다.
description = 'cor pca method generate',
# 배포하는 사람의 이름을 작성합니다.
author = 'changje.cho',
# 배포하는 사람의 메일주소를 작성합니다.
author_email = 'qkdrk7777775@gmail.com',
# 배포하는 패키지의 url을 적어줍니다. 보통 github 링크를 적습니다.
url = 'https://github.com/qkdrk7777775/pca_cj',
# 배포하는 패키지의 다운로드 url을 적어줍니다.
download_url = 'https://github.com/qkdrk7777775/pca_cj/archive/master.zip',
# 해당 패키지를 사용하기 위해 필요한 패키지를 적어줍니다. ex. install_requires= ['numpy', 'django']
# 여기에 적어준 패키지는 현재 패키지를 install할때 함께 install됩니다.
install_requires = [],
# 등록하고자 하는 패키지를 적는 곳입니다.
# 우리는 find_packages 라이브러리를 이용하기 때문에 아래와 같이 적어줍니다.
# 만약 제외하고자 하는 파일이 있다면 exclude에 적어줍니다.
packages = find_packages(exclude = []),
# 패키지의 키워드를 적습니다.
keywords = ['correlation matrix principal component analysis'],
# 해당 패키지를 사용하기 위해 필요한 파이썬 버전을 적습니다.
python_requires = '>=3',
# 파이썬 파일이 아닌 다른 파일을 포함시키고 싶다면 package_data에 포함시켜야 합니다.
package_data = {},
# 위의 package_data에 대한 설정을 하였다면 zip_safe설정도 해주어야 합니다.
zip_safe = False,
# PyPI에 등록될 메타 데이터를 설정합니다.
# 이는 단순히 PyPI에 등록되는 메타 데이터일 뿐이고, 실제 빌드에는 영향을 주지 않습니다.
classifiers = [
'Programming Language :: Python :: 3',
'Programming Language :: Python :: 3.2',
'Programming Language :: Python :: 3.3',
'Programming Language :: Python :: 3.4',
'Programming Language :: Python :: 3.5',
'Programming Language :: Python :: 3.6',
'Programming Language :: Python :: 3.7',
],
)
__init__.py : 내용은 없어도 무방하나 없으면 패키지가 설치가 안됨.
README.md : github에서 보여질 문서
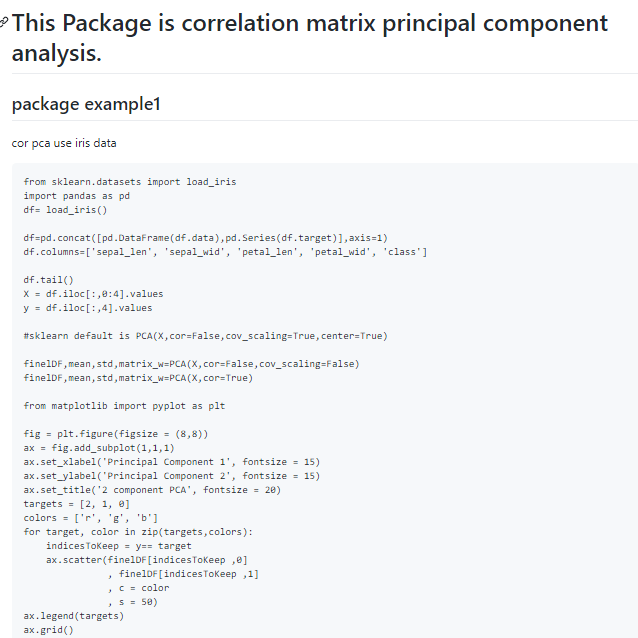
# This Package is correlation matrix principal component analysis.
## package example1
cor pca use iris data
```
from sklearn.datasets import load_iris
import pandas as pd
df= load_iris()
df=pd.concat([pd.DataFrame(df.data),pd.Series(df.target)],axis=1)
df.columns=['sepal_len', 'sepal_wid', 'petal_len', 'petal_wid', 'class']
df.tail()
X = df.iloc[:,0:4].values
y = df.iloc[:,4].values
#sklearn default is PCA(X,cor=False,cov_scaling=True,center=True)
finelDF,mean,std,matrix_w=PCA(X,cor=False,cov_scaling=False)
finelDF,mean,std,matrix_w=PCA(X,cor=True)
from matplotlib import pyplot as plt
fig = plt.figure(figsize = (8,8))
ax = fig.add_subplot(1,1,1)
ax.set_xlabel('Principal Component 1', fontsize = 15)
ax.set_ylabel('Principal Component 2', fontsize = 15)
ax.set_title('2 component PCA', fontsize = 20)
targets = [2, 1, 0]
colors = ['r', 'g', 'b']
for target, color in zip(targets,colors):
indicesToKeep = y== target
ax.scatter(finelDF[indicesToKeep ,0]
, finelDF[indicesToKeep ,1]
, c = color
, s = 50)
ax.legend(targets)
ax.grid()
#pca prediction
a=PCA(X[1:50],cor=False,cov_scaling=False)
#prediction
pred=(X[51:,:]-a[1]).dot(a[3])
```
## package example2
```
#sklearn kernel PCA method but scale is diffrence
X, y = make_moons(n_samples=100, random_state=123)
X_skernpca ,lambdas= kernel_PCA(X,n_components=2, gamma=15,scaling=False)
plt.scatter(X_skernpca[y == 0, 0], X_skernpca[y == 0, 1],
color='red', marker='^', alpha=0.5)
plt.scatter(X_skernpca[y == 1, 0], X_skernpca[y == 1, 1],
color='blue', marker='o', alpha=0.5)
plt.xlabel('PC1')
plt.ylabel('PC2')
plt.tight_layout()
plt.show()
```
setup.cfg
[metadata]
description-file = README.md
.gitignore : 깃 등록시 무시되게 설정해주는 파일.
# vscode
.vscode/
# Byte-compiled / optimized / DLL files
__pycache__/
*.py[cod]
*$py.class
# C extensions
*.so
# Distribution / packaging
.Python
build/
develop-eggs/
dist/
downloads/
eggs/
.eggs/
lib/
lib64/
parts/
sdist/
var/
wheels/
pip-wheel-metadata/
share/python-wheels/
*.egg-info/
.installed.cfg
*.egg
MANIFEST
# PyInstaller
# Usually these files are written by a python script from a template
# before PyInstaller builds the exe, so as to inject date/other infos into it.
*.manifest
*.spec
# Installer logs
pip-log.txt
pip-delete-this-directory.txt
# Unit test / coverage reports
htmlcov/
.tox/
.nox/
.coverage
.coverage.*
.cache
nosetests.xml
coverage.xml
*.cover
.hypothesis/
.pytest_cache/
# Translations
*.mo
*.pot
# Django stuff:
*.log
local_settings.py
db.sqlite3
# Flask stuff:
instance/
.webassets-cache
# Scrapy stuff:
.scrapy
# Sphinx documentation
docs/_build/
# PyBuilder
target/
# Jupyter Notebook
.ipynb_checkpoints
# IPython
profile_default/
ipython_config.py
# pyenv
.python-version
# celery beat schedule file
celerybeat-schedule
# SageMath parsed files
*.sage.py
# Environments
.env
.venv
env/
venv/
ENV/
env.bak/
venv.bak/
# Spyder project settings
.spyderproject
.spyproject
# Rope project settings
.ropeproject
# mkdocs documentation
/site
# mypy
.mypy_cache/
.dmypy.json
dmypy.json
# Pyre type checker
.pyre/
git init
git add .
git commit -m 'repo init'
git remote add origin http://github.com/<깃계정>/<패키지명>.git
git push -u origin master
패키지 등록을 위해 3가지 패키지가 요구
setuptools, wheel, twine
pip install setuptools wheel twine
python setup.py bdist_wheel
명령어 실행시 파일이 생성 되는데 dist 경로를 확인

twine upload dist/pca_cj-0.2-py3-none-any.whl
이제 pip install pca_cj로 다운로드 받아 실행하면되며,
python에서는
from pca_cj import <function명>의 형태로 사용하면 된다.
만약 도중에
fatal: remote origin already exists 란 애러가 발생할 시
git remote rm origin 를 사용하여 remote origin을 제거하고 다시 진행하면 설치 될 것이다.
참고 : https://doorbw.tistory.com/225
파이썬(PYTHON) #25_ 파이썬 패키지 등록하기 (pip 배포하기)
안녕하세요. 문범우입니다. 이번 포스팅에서는 파이썬 패키지를 배포하는 방법에 대해서 함께 살펴보도록 하겠습니다. 1. pip: 파이썬 패키지 관리자 파이썬 패키지를 배포하는 방법에 대해 설명
doorbw.tistory.com
'python' 카테고리의 다른 글
| matplotlib 시각화 정리 [여러 그림 그리기, quiver plot] (0) | 2020.11.05 |
|---|---|
| pypy (0) | 2020.08.31 |
| python gridSearch, RandomSearch (0) | 2020.07.30 |
| 명령프롬프트로 anaconda 열기 (0) | 2020.07.01 |
| pandas-profiling (0) | 2020.06.11 |
python gridSearch, RandomSearch
파이썬은 쓰면 쓸 수록 제공하는 부분에서는 친절하고 제공 안하는 부분에 대해서는 불친절한 것 같다.
pandas data frame 형태 데이터를 gridSearch 를 한번 해보려했는데 구조가 뭔가 복잡해서
검색해도 바로 찾지 못하겠어서 공유를 하고자 한다.
https://scikit-learn.org/stable/
scikit-learn: machine learning in Python — scikit-learn 0.23.1 documentation
Model selection Comparing, validating and choosing parameters and models. Applications: Improved accuracy via parameter tuning Algorithms: grid search, cross validation, metrics, and more...
scikit-learn.org
위 사이트는 scikit-learn 사이트이다. 이 사이트를 왜 공유하냐면 모델마다 하이퍼파라메터가 상이한데 이에 해당하지 않으면 에러가 뜨기 때문이다.
사실 영어를 잘하면 도큐먼트를 읽으면되나 시간도 없고.. 영어도 못하고..
우선 scikit-learn에서 제공하는게 뭔지 잘 모르겠다면,
anaconda의 경로로 가보자.
default세팅이라고하면, 사용자>계정명>Anaconda3>Lib>site-packages>sklean에 있을 것이다.
가상환경의 경우, 사용자>계정명>Anaconda3>envs>가상환경명>Lib>site-packages>sklean이다.
무튼 잘 들어왔다면, 다양한 폴더들이 있는데
우리가 import sklearn을 하지 않고
from sklearn.svm import BaseCrossValidator를 임력했다고하면,
sklearn패키지 안에 svm이라는 폴더안에 객체인 BaseCrossValidator를 의미한다.
BaseCrossValidator에 해당하는 부분은 __init__.py 파일에 있는 것 같다.
다시 본론으로 grid Search를 어떻게 하느냐로 돌아가겠다.
우선 document에서 우리가 쓰고자 하는 모델을 검색해보자.
RandomForestRegressor를 쓰고자 한다면

아래와 같이 입력.
입력에는 parameter가 다양하게 있는데
이를 grid search 할 수 있다.
from sklearn.ensemble import RandomForestRegressor
rf=RandomForestRegressor()grid search 할 목록을 딕셔너리의 형태로 구성해보자.
rf_grid={'criterion':['mse','mae'],
'max_features':['auto','sqrt','log2',None]}다음과 같이 구성되었다면
from sklearn.model_selection import GridSearchCV
model=GridSearch(rf,rf_grid)
model.fit(X_train,Y_train)
이렇게 간단히 할 수 있다.
'python' 카테고리의 다른 글
| pypy (0) | 2020.08.31 |
|---|---|
| python package 생성 (0) | 2020.08.17 |
| 명령프롬프트로 anaconda 열기 (0) | 2020.07.01 |
| pandas-profiling (0) | 2020.06.11 |
| anaconda 활용법 (0) | 2020.06.04 |
명령프롬프트로 anaconda 열기
최근에 아나콘다 프롬프트가 사라지는 황당한 경우를 목격하였다.
별다른 문제가 없을 줄 알았는데 spyder에서는 conda를 못 사용하는 상황이였고 주피터 노트북은 설치가 안되있는 상황이였다.
이를 해결하는 방법은 다음과 같다.
아나 콘다가 설치된 경로로 이동한다.

해당경로에는 Scripts라는 폴더가 있을 것이다. 여기서 activate.bat이라는 배치파일을 실행하면 아나콘다가 열리는 구조인것 같다.
따라서 다음과 같이 명령프롬프트를 입력하면 아나콘다 형식으로 접속된다.
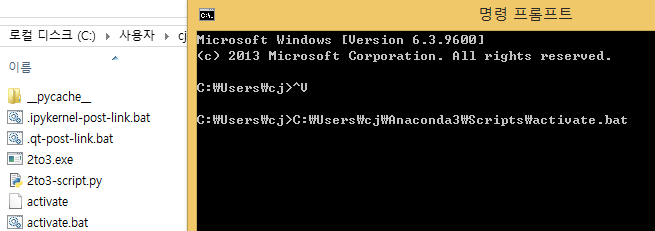
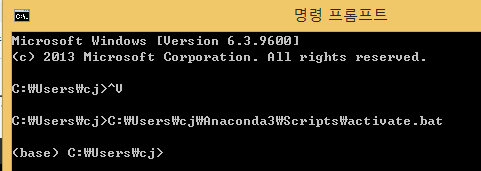
'python' 카테고리의 다른 글
| python package 생성 (0) | 2020.08.17 |
|---|---|
| python gridSearch, RandomSearch (0) | 2020.07.30 |
| pandas-profiling (0) | 2020.06.11 |
| anaconda 활용법 (0) | 2020.06.04 |
| [postgreSQL] python에서 postgreSQL과 shape file 사용하기 (0) | 2020.03.15 |
보호되어 있는 글입니다.
내용을 보시려면 비밀번호를 입력하세요.
win32com.client CLSIDToPackageMap 에러 해결
win32com 을 잘 사용하다가 갑자기 위와 같은 애러가 발생하는 경우가 있다.
이런 경우 뒤에 작업이 진행 되지 않기에 이를 해결하려 하지만 계속 애러가 났었다.
이 때 C:\User\계정명\AppData\Local\Temp\gen_py 폴더를 제거하게 되면 에러 없이 다시 진행이 된다.
지우고 커널을 다시 킨 뒤 실행하게 되면 다시 해당 폴더가 생기고 에러는 해결되니 참고하기 바란다.
https://stackoverflow.com/questions/33267002/win32com-client-open-excel-error
'python > hwp' 카테고리의 다른 글
| [파이썬 ] 한글 자동화 보안모듈 등록 (0) | 2020.03.29 |
|---|
