[Selenium] 기상자료 크롤링
크롤링의 종류와 개요는 아래에 포스팅 해두었으니, 궁금하신 분은 먼저 읽고 오기를 바란다.
크롤링과 python
크롤링, 스크래핑 데이터 분석의 자료수급을 위해 요즘 같이 활용되는 기술로 크롤링이라 부르는 기술이 있다. 크롤링은 크롤러가 웹을 돌아다니는 작업을 말하고, 스크래핑은 크롤러를 통해
pycj92.tistory.com
사용될 패키지
크롤링에 사용될 패키지는 다음과 같으며, 간단한 용도는 다음과 같다.
자료 저장 경로나 디렉토리조회 관련 용도의 os 패키지
자료 추출을 위한 re 패키지
크롤러에 지연을 주기위한 time 패키지
원하는 곳으로 파일 이동을 위한 shutil 패키지
사용하지는 않았지만, 향후 자동로그인을 위한 threading 패키지
마지막으로 크롤링에 사용되는 selenium 패키지
import os
import re
import warnings
from time import sleep
import pandas as pd
import shutil
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
from selenium.webdriver.support.ui import Select
import threading 사용 환경 설정
본격적인 크롤링에 앞서, 환경을 세팅해보자.
환경을 세팅하기 위해서는 크롬드라이버를 별도로 다운로드 받아야하는데 사용하고 있는
크롬의 버전과 동일해야 한다.
아래는 크롬드라이버의 버전을 확인하는 과정이다.
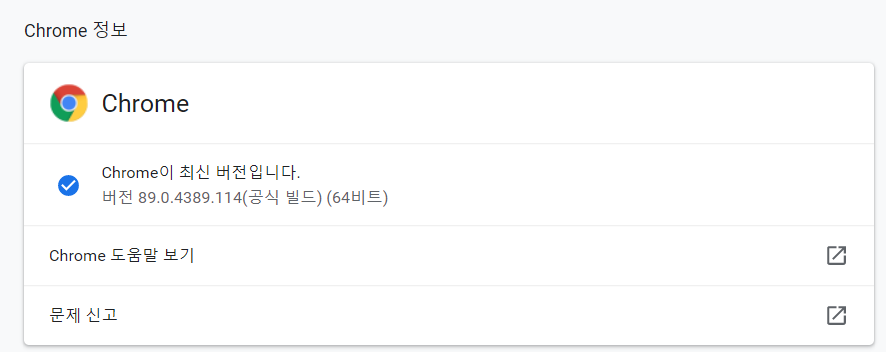
현재 내 컴퓨터는 89.0 버전이라는 것을 확인할 수 있다.
아래 링크는 크롬드라이버를 설치할 수 있는 사이트이다. 해당 사이트에서 내 버전인 89.0 windows 버전으로 다운받자.
chromedriver.chromium.org/downloads
Downloads - ChromeDriver - WebDriver for Chrome
WebDriver for Chrome
chromedriver.chromium.org
다운 받았다면, 다운받은 chromedriver.exe파일을 자주사용하는 경로로 이동시키도록 하자
(나는 c:/selenium으로 설정함, c:/selenium/chromedriver.exe)
본격적인 크롤링
간략히 설명하자면, driver_path는 chrome driver의 경로를 의미하며, download_path는
인터넷의 자동 다운로드 경로를 의미한다.
setting함수를 사용하게 되면, 기상자료개방포털 홈페이지로 이동하게 된다.
login 함수를 사용하게 되면, login을 수행하며, 성공하면 True를 반환한다.
logout 함수를 사용하게 되면, logout을 수행하며, 성공하면 True를 반환한다.
close와 quit함수는 인터넷창을 닫는다.
class KMA:
def __init__(self,driver_path=r'c:\selenium\chromedriver.exe',
download_path=r'D:\downloads',options = Options(),time=5):
self.down_dir=download_path
self.driv_path=driver_path
self.options=options
options.add_experimental_option("prefs", {
"download.default_directory": self.down_dir})
self.time=time
self.thread=threading.Timer(time,self.auto_login)
def setting(self):
try:
self.driver.quit()
except:
1
self.driver= webdriver.Chrome(self.driv_path, options=self.options)
self.driver.get('https://data.kma.go.kr/cmmn/main.do')
def login(self,kma_id,kma_pass):
try:
self.driver.maximize_window()
self.driver.find_element_by_css_selector('a#loginBtn').click()
self.driver.find_element_by_css_selector('input#loginId.inp').send_keys(kma_id)
self.driver.find_element_by_css_selector('input#passwordNo.inp').send_keys(kma_pass)
self.driver.find_element_by_css_selector('button#loginbtn.btn_login').click()
return True
except:
print('이미 로그인 중입니다.')
return False
def logout(self):
try:
self.driver.maximize_window()
self.driver.find_element_by_css_selector('a#logoutBtn').click()
return True
except:
print('이미 로그아웃 되어있습니다.')
return False
def close(self):
self.driver.close()
def quit(self):
self.driver.quit()
login, logout 을 매번 수행하기 귀찮으므로 login_loof함수를 사용하게 되면 다시 로그인을 수행한다.
auto_login, start, cancel함수는 현재 수정중이다.
download는 자료를 다운로드 받는 함수이다.
data_type은 지상기상관측자료와 해양자료 즉, Aws, Asos, Agr, FargoBuoy, Buoy, Rh가 될수 있으며,
new_path는 최종적으로 저장될 경로를 의미하고, time_type은 시간자료, 분자료, 일자료 등이 될 수 있다.
def login_loof(self,kma_id,kma_pass):
self.logout()
self.login(kma_id,kma_pass)
def auto_login(self,kma_id,kma_pass):
self.login_loof(kma_id,kma_pass)
self.thread=threading.Timer(self.time,self.auto_login)
self.thread.start()
def start(self):
self.thread.start()
def cancel(self):
self.thread.cancel()
def download(self,data_type,download_day,new_path,query,time_type='시간 자료'):
""" 사이트 이동 """
try:
if data_type in ['Aws','Asos','Agr']:#Asos,Aws,Agr
self.driver.get(f'https://data.kma.go.kr/data/grnd/select{data_type}RltmList.do?pgmNo=')
elif data_type in ['FargoBuoy','Buoy','Rh']:#data_type='FargoBuoy'#Buoy,lb(Rh),FargoBuoy
self.driver.get(f'https://data.kma.go.kr/data/sea/select{data_type}RltmList.do?pgmNo=')
else:
raise
except:
print('Asos, Aws, Agr, FargoBuoy, Buoy, Rh')
""" 시간 타입 """
Select(self.driver.find_element_by_id('dataFormCd')).select_by_visible_text(time_type)
""" 변수 선택 """
self.driver.find_element_by_id('ztree1_1_check').click()
""" 전체 지점 선택 """
if self.driver.find_element_by_css_selector('a#ztree_1_check').get_attribute('title')=='전체선택 안됨':
self.driver.find_element_by_css_selector('a#ztree_1_check').click()
""" 시작 기간 설정 """
self.driver.execute_script('document.querySelector("input[id=startDt_d]").removeAttribute("readonly")')
self.driver.execute_script(f'document.querySelector("input[id=startDt_d]").value = "{query}"')
""" 끝 기간 설정 """
self.driver.execute_script('document.querySelector("input[id=endDt_d]").removeAttribute("readonly")')
self.driver.execute_script(f'document.querySelector("input[id=endDt_d]").value = "{query}"')
if time_type=='시간 자료':
self.driver.find_element_by_xpath(f'//select[@name="startHh"]/option[@value="{st_time}"]').click()
self.driver.find_element_by_xpath(f'//select[@name="endHh"]/option[@value="{ed_time}"]').click()
""" 조회 """
self.driver.execute_script('goSearch();')
sleep(1)
if data_type=='FargoBuoy':
pd.read_html(self.driver.find_elements_by_css_selector('table.tbl')[0].get_attribute('outerHTML'))
else:
pd.read_html(self.driver.find_elements_by_css_selector('table.tbl')[1].get_attribute('outerHTML'))
""" 다운로드 """
self.driver.execute_script('downloadRltmCSVData();')
sleep(1)
try:
self.driver.find_element_by_css_selector('div#divPopupTemp.back_layer').get_attribute('id')
self.driver.find_element_by_id("reqstPurposeCd7").click()
except:
1
self.driver.execute_script('fnRltmRequest();')
#A.quit()
before_files=[i for i in os.listdir(self.down_dir) if re.compile('.csv').findall(i)]
before=(len(before_files))
sleep(5)
after_files=[i for i in os.listdir(self.down_dir) if re.compile('.csv').findall(i)]
after=(len(after_files))
if before!=after:
down_file=list(set(after_files)-set(before_files))[0]
shutil.move(f'{self.down_dir}/{down_file}',new_path)
자료를 하루만 받을게 아니라서, download_range함수를 만들었다.
n_download_login_loof는 '자료를 몇개 받았을 때 재로그인할지'에서 몇개를 의미한다(default : 20)
over_write는 기존에 같은 자료가 있으면, 넘어갈지 덮어쓸지를 의미한다.
def download_range(self,date_list,data_type,kma_id,kma_pass,\
n_download_login_loof=20,st_time='00',ed_time='23',time_type='시간 자료',\
down_dir='d:/downloads/aws',over_write=False):
_n_download_login_loof=0
down_error=list()
old_down_dir=os.listdir(down_dir)
for download_day in date_list:
_n_download_login_loof=_n_download_login_loof+1
if _n_download_login_loof%n_download_login_loof==1:
self.login_loof(kma_id,kma_pass)
sleep(3)
query=download_day.strftime('%Y%m%d')
move_file_name=f'{data_type}_{query}_{time_type}.csv'
new_path = f'{down_dir}/{move_file_name}'
n_download_login_loof=n_download_login_loof+1
if over_write==False:
if not move_file_name in old_down_dir:
try:
print(download_day)
self.download(data_type,download_day,new_path,query,time_type)
except:
down_error.append(download_day)
else:
try:
print(download_day)
self.download(data_type,download_day,new_path,query,time_type)
except:
down_error.append(download_day)
return down_error
def date_to_filename(self,date_list,down_dir, data_type, time_type):
return [f'{data_type}_{i.strftime("%Y%m%d")}_{time_type}.csv' for i in date_list]
대충 사용방법은 아래를 따라하면 된다.
A=KMA(time=60*3,download_path=r'D:\downloads\temp')
#A=KMA(time=60*3)
A.setting()
A.login_loof(kma_id=아이디,kma_pass=비밀번호)
start_day = '2010-01-01';end_day = '2020-12-31';data_type='Asos'#Asos,Aws
st_time='00';ed_time='23';time_type='시간 자료';down_dir='d:/downloads/asos';over_write=False
start_day = pd.Timestamp(start_day)
end_day = pd.Timestamp(end_day)
date_list=pd.date_range(start_day,end_day,freq='d')
#start_day = pd.Timestamp(start_day)
#download_day=start_day
#query=download_day.strftime('%Y%m%d')
#move_file_name=f'{data_type}_{query}_{time_type}.csv'
#new_path = f'{down_dir}/{move_file_name}'
#A.download(data_type,download_day,new_path)
down_error_list=A.download_range(date_list,data_type,n_download_login_loof=20,\
kma_id=아이디,kma_pass=비밀번호,down_dir='d:/downloads/asos')
#query=download_day.strftime('%Y%m%d')
set(A.date_to_filename(date_list, down_dir, data_type, time_type))-set(os.listdir(down_dir))
A.quit()